This really is a problem, and it gets more serious with larger tables.
I’m going to explain what the problem is from an analyst’s point of view.
What LIKE does for us
Like in the SQL WHERE clause
LIKE identifies rows which match the criteria. It can be used with character columns and combined with other conditions.
The first time I encountered this statement I was amazed that it worked at all! This simply demonstrates how SQL protects us from what is really happening underneath the surface.
Like with a trailing wildcard using an index
Appearances can be deceptive. LIKE only appears to match the search argument against the contents of the table column. It has to use an index in order to perform properly. The entries in the index are sorted. SQL uses the sort sequence with “trailing” wildcards, to get to the first match quickly, and then ignore any entries past the last match.
The problem with leading wildcards
Valid LIKE criteria – But two may cause problems
SQL cannot use an index to matching entries when there is a leading wildcard. As a consequence it will probably scan the whole table. This will work but it may take longer than you want.
The problem gets worse for tables with more rows because with a leading wildcard LIKE has to test every row.
There will be times when you need to use a leading wildcard it in a query. Go ahead and use it, just expect poor performance. If this query which will be used repeatedly, or in a program, then discuss what you are trying to do with the people who look after your database.
Summary
Phil Factor describes leading wildcards with LIKE as an SQL Smell. This may be unavoidable in some ad-hoc queries, but you should treat it with caution if you intend to reuse the query or use it with large tables.
Where next?
The next, and final, blog post is on “Floating Point Numbers”. Do you use floating point numbers in your database? Phil Factor thinks this is an SQL Smell too. Find out why in the next article.
Phil Factor identifies several SQL Smells associated with the use of DateTime, Date and Time data-types. Using the wrong types will waste space, harm performance and create “odd” behaviour.
If you are clear about what you are recording, you will avoid these issues. I prefer to say what I want, and let an expert choose the best date-types. In other words, I prefer to separate the analyst and designer roles. That way I avoid suggesting the wrong types.
DateTime, Date or Time – Which do you need?
DateTime columns which contain only Date or Time contribute two of SQL Smells. This wastes space, both in storage and in memory (which will degrade performance).
There is something worse here. Using DateTime in this way suggests we are not clear about what we want. This lack of clarity encourages the designer to “hedge their bet” by using DateTime.
How precise do you need to be?
Business Systems need to record dates and times, but they don’t need great precision. For many business transactions, the nearest second or even minute is adequate. In some cases recording extra precision can be misleading.
Storing Durations
For a “Period” you need to know 3 things: Start, End and Duration. You only need to store two out of the 3. The third value can always be calculated if you have the other two.
Finding if an Event is inside a Period is easier using Start and End
Storing the “start” and “end” is more flexible. It is straightforward to work out if an event took place within a given period.
Finding if Periods Overlap is easy using Start and End times
Telling if periods overlap is easy too.
If you decide to store a duration you must specify the units you intend and the precision you need. (As Phil puts it “milliseconds? Quarters? Weeks?”). Do not be tempted to store a duration in a “Time” data-type! “Time” is intended for “Time-of-day” not duration.
Dates and Times: Choosing the right data-type – Some simple questions
Choosing appropriate data-types for dates and times is not difficult, if you go about it the right way.
Divide the job into two steps: “The Requirement” and the “The Most suitable technical data-type”. Do the two steps separately, taking into account any local standards and conventions.
The Requirement
Is this an “Event” (a “Point in Time”) a “Period” or a “Duration” (both have beginning and an end)?
Event: What is the best way to represent this data? Should it be a “Date” or a “Time”? Does it really need “Date-time”?
Duration: What are the units and scale of this duration?
How precise do you need the value to be? You may surprise yourself.
How long do you expect this system (and the data in it) to last?
The Most Suitable Technical Data-type
Technical Properties of Date and Time data-types in Microsoft SQL Server
Use the table (based on Microsoft’s Documentation) to choose the best data-type for your needs. This table is for SQL Server. Other database managers will have similar tables.
Microsoft recommends using DATETIME2 in preference to DATETIME for new work (it takes up less space and is more accurate). Providing the maximum date is acceptable, I would consider SMALLDATETIME for business transactions (but you do risk creating a “Year 2000 problem” if the data turns out to have a long life).
If your system will span several time-zones, then you should definitely consider the benefits of using the DATETIMEOFFSET data-type.
Summary
The DateTime, Date and Time data-types can all cause SQL Smells when they are used inappropriately. Problems can be avoided by following some simple guidelines.
Where next?
Phil Factor doesn’t like “SELECT *”. Find out why in the next article.
NULLs are a perennial problem. Nobody likes them. They confuse developers and users and many analysts do not really understand them.
The concept of NULL allows us to say that there are things that we do not know.
In his article on SQL Smells, Phil Factor associates several smells with NULLs. In this post I’ll explain how to avoid using NULLs and how to use them properly when they are necessary.
Why do we need NULLs at all? What is the benefit and what is the cost?
NULL has a simple meaning with wide-ranging and surprising consequences. NULL means the value is unknown. And this in turn means that the result of any calculation or concatenation which uses this value must also be unknown!
NULL is a feature of SQL. The benefit of allowing NULL or “three valued logic” (TRUE/FALSE/UNKNOWN) is that it allows a database to record that there are things we do not know. The cost of having them is that any calculation or concatenation which uses this value must also be unknown! This confuses many people.
Reasons for needing NULL
There are many reasons why we might not have data to put into a column. Thinking about why we are considering defining a column as NULLable will encourage us to consider alternatives.
The structural NULL – Permanent sub-types
Customer with Sub-types which may cause NULLs
Sometimes we want to combine two entities into a single “super-type” table. There are attributes of Person will never be used for Business (and vice-versa). These missing values will need NULLs.
The structural NULL – Lifecycle subtypes
Order with Lifecycle sub-types which may cause NULLs
Something similar can happen if we combine all the steps of a entities lifecycle into a single table. The attributes of the later stages will always be empty (NULL) until that stage is reached. These later steps often contain dates or times.
In both cases involving sub-types it may be possible to splitting the sub-types into separate tables. Consider whether it is worth the effort and make sure you avoid the pitfalls of sub-types in SQL.
Data that will never be there
Attributes and Values for an “Address”
Entities like “Address” are frequently modelled with attributes like “AddressLine_”. In many cases there will never be values for the later lines. They will not be mandatory in the user interface, but do they need to be NULL? Consider whether allowing them to default to “spaces” or an empty string, would be better and whether it would have any bad effects.
There are some things which should hardly ever allow NULL. This includes all keys and identifiers. Avoid allowing short titles or descriptions to be NULL (For long descriptions allowing NULLs is understandable).
Unavoidable NULLs
Attributes and Values for a “Person” Entity – Sometimes NULL is hard to avoid
There are some attributes where allowing NULL is hard to avoid. Life insurance and pensions companies may need a “date of death” for their customers! Having a column with allows NULL is often the easiest way of handling this.
You should resist the temptation to use “magic dates” or inappropriate data-types in order to avoid allowing NULL. The consequences are far worse than the problem.
Summary
NULLs are a problem, nobody likes them but they are necessary. Many problems with NULLs can be avoided by two rules:
Remember that NULL means “unknown value” and this has consequences.
Ask “_why_ don’t we have this data?”
In many cases NULLs can be avoided by data modelling – that means the analyst has to do work in the Conceptual or Logical Model.
Where next?
The next article is about another smell: having the same name for different things!
SQL Indexes – A Goldilocks problem for analysts or an SQL Smell
Database Indexes are something which a lot of analysts ignore as being “too technical”. This is a pity.
Several SQL Smells in Phil Factor’s article point at possible bad decisions. Thinking in the Logical Model can improve these decisions.
Choosing the correct indexes is a typical “Goldilocks Problem”: not too few, not too many, just the right number! Bad or inadequate requirements will contribute to designers making bad decisions. Phil Factor describes having the wrong indexes as an SQL Smell!
What is an Index and what does it do for us?
If you are an analyst, you may not know exactly what an index is. In non-technical terms, an index provides a quick way for the database manager to find the rows it needs in a table. There are several sorts of index.
An index is a “thing” in its own right. An index takes up space in the database. Updating an index costs effort. The main benefit of an index is that it makes select or read operations faster.
Types: Unique, Non-Unique, Clustered
There are three main kinds of index: Unique, Non-Unique and Clustered.
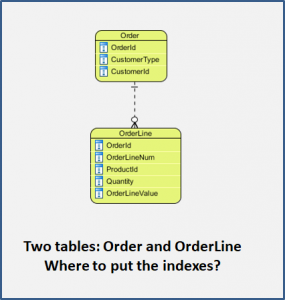
Imagine that we have a very simply database consisting of 3 tables:
Customer (not shown in the diagram)
Order
OrderLine
Two tables: Order and OrderLine – Where to put the indexes?
Unique Indexes:
Candidate Unique Indexes on an “Order” SQL table
In the Order table we can see three columns which might be used to identify the order
If you are not familiar with GUIDs, they are a way of assigning identifiers or “keys”. They are worth finding out about. It would be unusual to expect a human being to type in a GUID. An “OrderNum” (which paradoxically might contain letters!) would be more convenient for the users.
We expect all three: OrderId, GUID and OrderNum, to be unique. Therefore, all three are candidates for Unique Indexes. If an application attempts to create a duplicate value in a column which has a unique index, then the database manager will raise an error and reject the transaction.
Non-Unique Indexes for Foreign Keys
Candidate Indexes on an “OrderLine” SQL table
In the OrderLine table you can see two columns which identify things in other tables: OrderId and ProductId. These are Foreign Keys. In this case we cannot say they are unique, but they are candidates for non-unique indexes.
We could also have used OrderNum or OrderGUID as Foreign Keys into Order.
It is good practice for the rows in the OrderLine table to have a unique identifier. There are two common ways of doing this.
We can assign an OrderLineId (which is unique across the whole table) or
we can use the combination of OrderId and OrderLineNum which together would identify a row.
In this example, both OrderLineId and the OrderId and OrderLineNum combination are (seperate) candidate unique indexes.
Clustered Indexes
The order of the rows in an SQL table is specified by the Clustered Index. Each table can have only one clustered index. The clustered index must be unique.
People often make the “primary key” the clustered index, but it is worth considering other options. In the example, OrderLines can be added to an order after it has been created.
Using the OrderId, OrderLineNum index as the clustered index would make the database store all the “lines” for one order together (whenever they were added to the order). That may be more efficient for retrieval. Phil Factor identifies two smells with the choice of clustered indexes.
Non-Unique Indexes for Searching
Candidate Indexes on a “Customer” SQL table – A Non-Unique index on Name would help searches
Columns which will be used for searching should be considered candidates for a non-unique index.
The role of Analysts in choosing Indexes and Index types
Indexes are usually specified in the “Physical Model”. The analyst can help the database designer make the right decisions, by applying a little thought. The analyst should not try to pre-empt the designers decisions. They should aim to assist by identifying relevant “candidates”.
Summary
Indexes enforce business rules like uniqueness in an SQL database. They influence database performance. Considering candidate indexes in the Logical Model and even the Conceptual Model will help database designers make better decisions.
Where next?
The next article is about the smell of nothing, or “Nulls”. Nulls present problems for developers and database designers.
One of the “SQL smells” Phil Factor identifies in his article is the presence of “God Objects” in your Database or design. I agree with him, except that I would call them “very wide tables”. If you find them, then you may have a problem with the Conceptual Model you are using, or possibly t you should be considering using a different tool. In other words, you have a problem with your requirements. You have a “Requirements Smell”.
How many columns make a “God Object” or wide table?
How many columns can you have in an SQL table?
Let’s start with the obvious question: How many columns make a “God Object” or wide table? The maximum number of columns you are allowed to have in a table varies with database manager. For example:
What the actual numbers are can depend on a lot of technical things. One hundred is still a big number.
Database management software will handle wide tables up to their limits. As with most things, when you approach the limit you will start to encounter difficulties, but that is missing the point. Even 100 columns may indicate a problem.
Why are “God Objects” or wide tables a problem?
The reasons with “God Objects” or wide tables cause an SQL Smell are technical, practical and what you might term business, or even philosophical problems. I’m a Business Analyst, so I’m going to start from the “Conceptual” end, with the Requirements for the database, and then look at the problems which these tables may cause in Development and then when the system is in operation. Also remember, that if we eliminate problems at the conceptual end, then we’re not going to encounter them further on. Wide tables are most certainly a problem with starts at the “Conceptual Model” stage.
”Conceptual Model” or philosophical problems
Each row in a relational table is supposed to represent something. The “something” may be a concrete object in the real world, or it may be something abstract like a contract or a transaction. Would you be able to explain to the users of your system, or your business owners what a single row represents? If not, you are likely to encounter problems.
Thinking about the columns in this wide table, each column is contains a value. How are you going to present or update those values? 1000 fields would make for a very busy screen. Even some sort of graphical representation is likely to be complex. Do your users really need to see all this data together? While there isn’t a rule which says that the whole of an entity has to be presented on a single screen, or as a single report, it has to represent something. Finally, every column in a row provides one value for one thing at one time. Is that really so in your wide table?
Problems during development
“God objects” or wide tables encourage handling one big lump of data. That in turn is going to encourage the creation of complicated code. Maybe life would be easier for everyone if the data and the process descriptions were much more focused.
If you are in an Analyst role, then think about how you are going to explain what should (and should not) be happening with all these columns.
Remember, SQL tables have no concept of “grouping” of the columns. The columns have an order, but it is not something you should be relying on. If you can form columns into groups, then you should probably consider “normalizing” them into other tables.
Problems in operation
“God objects” or wide tables can cause problems when the system is being used. The volume of data each row contains may cause performance problems when rows are read from the table, when rows are updated and when new rows are created.
Why do we get “God objects”?
Wide tables often start from trying to convert large and complex paper forms or spreadsheets straight into table designs. It seems like a good idea at first, but it can get bogged down in unexpected complexity.
Think about your least favourite paper form, especially if it runs to several pages – maybe it’s a tax return or something similar. Obviously the physical form represents something. If you were specifying a system to work with it, then you would be tempted to have a single table where each row represented a single form, there was a column for every question and each cell contained one person’s answer to a question. It would be just like an enormous spreadsheet. Some early commercial computer systems were like that. They worked but they were inflexible.
One clue that something is going wrong (apart from the number of columns) is the number of columns which need to allow “NULL” values. How many times does “Not Applicable” appear when you are filling in the paper form?
How do we solve the problem of the wide table?
The answer is to think about what all these columns mean and then start applying Data Modelling or normalization techniques to break the data into more manageable and useable chunks. If you can from groups of columns then those groups may be candidate entities and therefore candidate tables.
If you need to use the order of similar columns then maybe you should be considering a different table design like the “Entity Attribute Value” (MVP) Pattern. But beware, because that can give rise to a bad smell too!
Excuses for “God Objects” and wide tables
Nothing in Information Technology is ever clear-cut. There are usually grey areas. One person may regard a table as too wide and another may regard it as OK. There is always room for some discussion. There are times when using a table that is a little wider than we would normally like is acceptable. Here are some of the reasons (or maybe that should be excuses) that you may here for wide tables.
It gets all the work done in one place, so that other programs can use the data. I don’t really buy this one. I suspect that someone is guessing what these other programs need. If the guess is wrong then someone is going to have to re-design the big, wide table. I continue to maintain that having discrete data and performing discrete actions is better.
Here is a specific case I found where someone wanted to retrieve data from 2000 sensors. This is a case where using something other than a relational database might be better in the first instance. Depending on the details it might also be a case where using the Entity Attribute Value (EAV) model is appropriate as well.
We are being given the data in the wide form from another system. This excuse I will accept, because it is really being imposed as an external requirement. But! If you need to do this, then you will need to do the work of working out what all those many columns mean, and you may have to break the wide row down into constituent parts.
Where next?
That’s addressed the “God Object” or “Wide table” smell. I’ve already mentioned the “Entity Attribute Value” (EAV) model a couple of times. I’m going to address why that may be give rise to a bad smell in the next post.