When I first read Phil Factor’s article on SQL Smells I had to look up Polymorphic Association to make sure that I understood what he was getting at. He’s right – this is a bad SQL smell! In my option it is one that can always be avoided.
But what is a “polymorphic association” in SQL?
Polymorphic Association
The reason I didn’t recognise Phil Factor’s polymorphic association, is that I knew by the name “alternative parent”. Polymorphic Association is probably known by other names too!
Relational Databases don’t recognise the idea the idea of sub-typing. The construction Phil Factor doesn’t like is the result of a flawed attempt to provide sub-typing.
We need to deal with some real situations like:
- “Customer” – has the sub-types:
- Person
- Corporate Entity (or “Business”)
- “Something we sell” (perhaps “Saleable item”?) – has the sub-types:
- Product
- Service
One way to do this is to define entities with sub-types. Doing sub-typing like this is a decision in the “Conceptual Model”. I need to point out that this is contentious because it builds the sub-types into the structure of the database itself. They become “hard-coded”.
In the rest of this article I’m going to use the “Customer: Person/Business” example.
What are we trying to achieve with “polymorphic association”?

In the example, someone has decided that we need to be able to record that Orders. Every Order is placed by either a Person or a Business. They have decided to have separate entities for Person and Business because they have different attributes. I have seen this conceptual requirement represented in several different ways, including:
- “Person” and “Business” surrounded by a box representing “Customer”
- A bar (often curved) drawn across the lines representing the relationships between Person or Business and Order.
- A Customer super-type with Person and Business sub-types.
The requirements are fairly simple:
- An Order is always placed by a Customer
- A Customer has to be a Person or a Business (as far as we are concerned, it can’t be both)
- So every Order is placed by either a Person or a Business.
What’s the problem with “polymorphic association”?

Phil Factor identifies a problem with “polymorphic association” when the database has reached the Physical Design stage. We can spot the potential for this problem to occur much earlier, when we are gathering Requirements and creating the Conceptual Design.
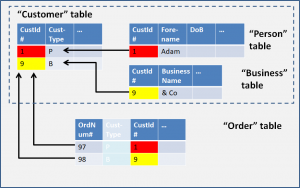
The problem in the Physical Design is that the Foreign Key in Order can refer to more than one table. The Cust_Type column tells use which table to use, but the database manager will not understand that. There are also further clues in the names of the various columns – If you look, you will notice a lot of use of the “super-type” in the names!
There are several problems with this Physical Design (Phil Factor’s article gives a more technical description):
- It is not easy to spot in the database, and that can be a problem in itself.
- It will result in complex procedural code.
- The Order table cannot use constraints to check that the foreign keys are valid.
- JOINs will be complicated
- This is construction is likely to perform poorly.
Polymorphic Associations – One solution
One solution to this problem is to recognise the “super-type” and make it explicit.
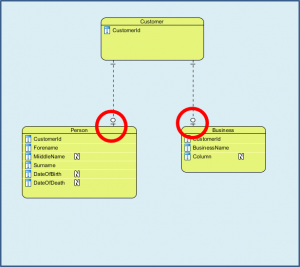
This slightly different construction with a Customer entity or table, enables us to solve the difficulties with the polymorphic association or alternative parent design. Notice how the ends of the relationships nearest the Person and Business tables are not the familiar “crow’s feet” but indicate that there must be either one or zero rows.
When we use this design all the Foreign Keys in the Order table now reference rows in the Customer table.
Spotting potential Polymorphic Associations
Deal with Polymorphic Associations during the Conceptual Design of the database. The indications that the Requirements create a situation where someone might try to use a Polymorphic Association are:
- There are several entities which are sufficiently similar that you consider having one entity, but are sufficiently different that you think multiple entities are justified.
- Something (like an order) needs to have an association with one (but only one) from among this group.
- Finally, watch for the word “OR” in your thinking. A Person OR a Business places and Order.
If you encounter these conditions, first you should challenge whether sub-typing is the correct solution. If you think it is, then use the single super-type and multiple sub-types form and avoid the polymorphic association.
Summary
I agree with Phil Factor. If you encounter the polymorphic association, stop! It is very unlikely to the the best solution in SQL. Don’t try to implement a polymorphic association. Create an explicit table for the super-type and then a separate table for each of the sub-types instead.
Where next?
In the next article I’m going to look at something which is responsible for a lot of bad “SQL Smells”. This multiple bad smell is the naming of SQL objects.