Do you use Floating Point numbers? Do you even know what they are?
Phil Factor regards Floating Point Numbers as an SQL Smell. That is to say “something which may cause problems”.
I’m going to explain why this is from an analyst’s point of view.
What are Floating Point numbers?

When I first started programming with FORTRAN we only had two sorts of numbers: integers and floating-point. You used integers for counting things and floating-point for calculations. It was that simple!
Modern languages and SQL databases allow other options, including precise decimal forms.
Floating point numbers use the binary equivalent of “Scientific” or “Engineering” notation. They stored differently to integers or decimals.
Their value is stored in two parts which are known as the “mantissa” and the “exponent”. This arrangement allows them to hold an enormous range of values very efficiently but at the expense of precision.
Problems with Floating Point numbers

Floating point numbers are intended for scientific or engineering calculations.
They can cause problems in normal business calculations.
- Arithmetic can cause rounding.
- Testing for equality can produce unexpected results.
- Phil Factor does not like them being used in keys or indexes.
Size and range of Numbers
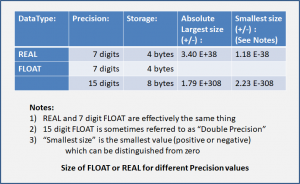
Floating-point numbers allow a very large and very small values. I cannot imagine examples of the extremes.

On the other hand, precise numeric data-types do not have the problems associated with floating point.
When should you use Floating Point numbers?

Very few businesses or “domains” need to use floating-point numbers. The table shows some example where they would be essential. In most cases these are estimates of extremely large, or very small, numbers.
Look at it like this: if you are working in engineering, astronomy or nuclear physics you may need floating-point numbers. You probably know if you really need them.
Summary
I recommend avoiding floating-point numbers. Phil Factor describes them as an SQL Smell which should be investigated. They are essential for some applications. When misapplied they will cause problems. If you think you need to use them, think hard.
Where next?
This is the concluding post in this sequence of articles. I’ve chosen to concentrate on potential problems which are likely to trouble analysts like me. Phil Factor’s original article identifies many more SQL Smells. These include details of design and programming. If you spend time working with SQL and specifying or designing databases, then I recommend the article both as background reading and as a handy reference.
As a Postscript: I don’t think Floating Point Numbers are bad, just people sometimes use them in the wrong way. Hugo Kornelis thought it was worth his time writing a post in defence of them – Float does NOT suck!