In his article on SQL Smells, Phil Factor describes identifies two “smells” associated with Constraints in SQL. He regards not using Referential Integrity as an SQL Smell.
In this post I will explain what a Constraint is, and how one kind of Constraint provides Referential Integrity.
What are CONSTRAINTs and what do they do for us?
A Constraint limits the values which are allowed in a column. The SQL database manager will use constraints to validate data. There are several types of constraint.
Phil Factor thinks that not enforcing Referential Integrity is usually bad (and I agree).
Referential Integrity and the FOREIGN KEY REFERENCES Constraint
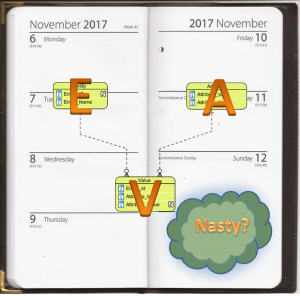
The FOREIGN KEY REFERENCES constraint on a column makes it a Foreign Key to another table. The Foreign Key must be present as a Primary Key in the referenced table. This is called Referential Integrity.
In the illustration, it is not possible for the Order table to contain a CustomerID which does not exist in the table Customer.

This is very powerful. The constraint makes the database manager check every change. Statements which would violate the Foreign Key constraint are rejected.
Performing the validation costs effort.
Phil Factor points out an additional benefit. The database manager may be able to use the Foreign Keys to improve performance of some queries.
Why wouldn’t you use Referential Integrity?
The arguments most frequently used for not implementing referential integrity are:
- Performance: I have already mentioned the “cost” of checking the constraints. This argument:
- Prejudice against logic in the database
- A desire to minimise the “load” on the database manager.
- Dirty Data: An “upstream” system may provide data which violates the constraint. Accepting this argument may mean importing faulty data, and the associated problems into your system!
“Staging tables” may be a better solution to this problem.
Both of these arguments are valid in some circumstances. There are times alternatives are better. Ask the following questions:
- How are you going to perform the validation?
- Which system components are going to perform the validation?
- Do you expect the alternative solution to perform better?
- Will the alternative solution be better in some way?
Not having answers to these questions is not really acceptable. Try and make a rational decision, based on numbers.
How Referential Integrity and Requirements interact
The Conceptual Data Model identifies business entities and relationships. Those relationships define the referential integrity requirements.
Not using referential integrity implies that:
- The system is going to allow invalid data, or
- The system is going to validate the data in some other way.
Summary
Foreign Key Constraints exclude some invalid data from the system. Orphaned records (eg non-existent Customers) are impossible.
Exceptions to this rule require a rational justification.
Where next?
In the next article I will look at “Check Constraints” which are a different way of ensuring valid data.