

Database Indexes are something which a lot of analysts ignore as being “too technical”. This is a pity.
Several SQL Smells in Phil Factor’s article point at possible bad decisions. Thinking in the Logical Model can improve these decisions.
Choosing the correct indexes is a typical “Goldilocks Problem”: not too few, not too many, just the right number! Bad or inadequate requirements will contribute to designers making bad decisions. Phil Factor describes having the wrong indexes as an SQL Smell!
What is an Index and what does it do for us?
If you are an analyst, you may not know exactly what an index is. In non-technical terms, an index provides a quick way for the database manager to find the rows it needs in a table. There are several sorts of index.
An index is a “thing” in its own right. An index takes up space in the database. Updating an index costs effort. The main benefit of an index is that it makes select or read operations faster.
Types: Unique, Non-Unique, Clustered
There are three main kinds of index: Unique, Non-Unique and Clustered.
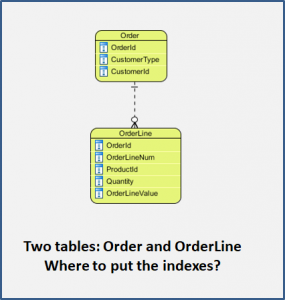
Imagine that we have a very simply database consisting of 3 tables:
- Customer (not shown in the diagram)
- Order
- OrderLine
Unique Indexes:

In the Order table we can see three columns which might be used to identify the order
If you are not familiar with GUIDs, they are a way of assigning identifiers or “keys”. They are worth finding out about. It would be unusual to expect a human being to type in a GUID. An “OrderNum” (which paradoxically might contain letters!) would be more convenient for the users.
We expect all three: OrderId, GUID and OrderNum, to be unique. Therefore, all three are candidates for Unique Indexes. If an application attempts to create a duplicate value in a column which has a unique index, then the database manager will raise an error and reject the transaction.
Non-Unique Indexes for Foreign Keys

In the OrderLine table you can see two columns which identify things in other tables: OrderId and ProductId. These are Foreign Keys. In this case we cannot say they are unique, but they are candidates for non-unique indexes.
We could also have used OrderNum or OrderGUID as Foreign Keys into Order.
It is good practice for the rows in the OrderLine table to have a unique identifier. There are two common ways of doing this.
- We can assign an OrderLineId (which is unique across the whole table) or
- we can use the combination of OrderId and OrderLineNum which together would identify a row.
In this example, both OrderLineId and the OrderId and OrderLineNum combination are (seperate) candidate unique indexes.
Clustered Indexes
The order of the rows in an SQL table is specified by the Clustered Index. Each table can have only one clustered index. The clustered index must be unique.
People often make the “primary key” the clustered index, but it is worth considering other options. In the example, OrderLines can be added to an order after it has been created.
Using the OrderId, OrderLineNum index as the clustered index would make the database store all the “lines” for one order together (whenever they were added to the order). That may be more efficient for retrieval. Phil Factor identifies two smells with the choice of clustered indexes.
Non-Unique Indexes for Searching

Columns which will be used for searching should be considered candidates for a non-unique index.
The role of Analysts in choosing Indexes and Index types
Indexes are usually specified in the “Physical Model”. The analyst can help the database designer make the right decisions, by applying a little thought. The analyst should not try to pre-empt the designers decisions. They should aim to assist by identifying relevant “candidates”.

Summary
Indexes enforce business rules like uniqueness in an SQL database. They influence database performance. Considering candidate indexes in the Logical Model and even the Conceptual Model will help database designers make better decisions.
Where next?
The next article is about the smell of nothing, or “Nulls”. Nulls present problems for developers and database designers.




