My previous post got me thinking. One thing leads to another as they say. The whole of my process really requires that you have a Data Model (aka Entity Relationship Diagram/Model and several other names). But what do you do if you don’t have one, and can’t easily create one?
What’s the problem?
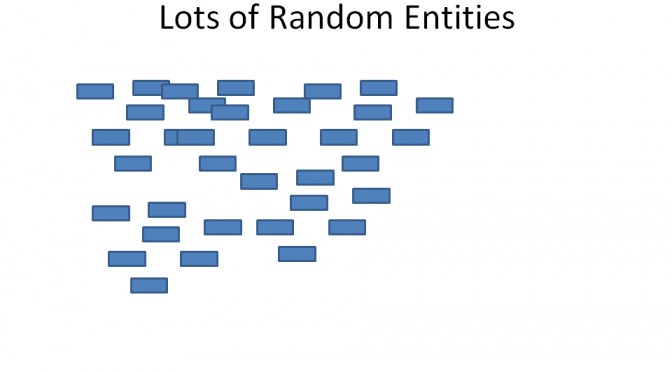
Suppose you have a database which has been defined without foreign key constraints. The data modelling tools use these constraints to identify the relationships they need to draw. The result is that any modelling tool is likely to produce a data model which looks like the figure below. This is not very useful!

Faced with this, some people will despair or run away! This is not necessary. Unless the database has been constructed in a deliberately obscure and perverse way (much rarer than some developers would have you believe) then it is usually possible to make sense of what is there. Remember, you have the database itself, and that is very well documented! Steve McConnellwould point out that the code is the one thing that you always have (and in the case of a database, it always matches what is actually there!).
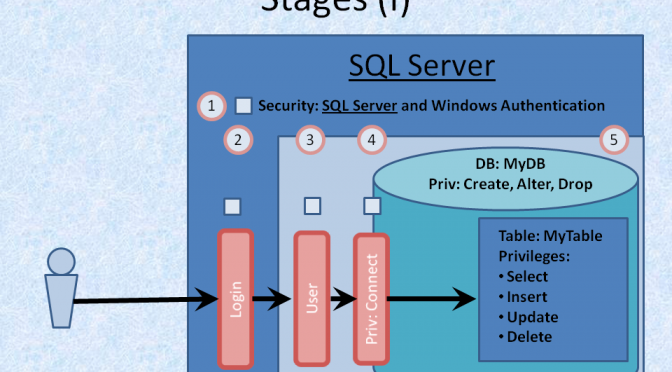
To do what I propose you will need to use the “system tables” which document the design of the database. You will need to know (or learn) how to write some queries, or find an assistant who understands SQL and Relational Databases. I’ve used MS SQL Server in my examples, but the actual names vary between different database managers. For example: I seem to remember that in IBM DB/2 that’s Sysibm.systables. You will have to use the names appropriate for you.
The method
“Method” makes this sound more scientific than it is, but it still works!
- Preparation: Collect any documentation
- “Brainstorm:” Try to guess the tables/entities you will find in the database.
- List the actual Tables
- Group the Tables: based on name
- For each “chunk”, do the following:
- Identify “keys” for tables: Look for Unique indexes.
- Identify candidate relationships: Based on attribute names, and non-unique indexes.
- Draw your relationships.
- “Push out” any tables that don’t fit.
- Move on to the next group.
- When you’ve done all the groups, look for relationships from a table in one group to a table in another.
- Now try and bring in tables that were “pushed out”, or are in the “Miscellaneous” bucket.
- Repeat until you have accounted for all the tables.
At this point you are probably ready to apply the techniques I described in my previous post (if you haven’t been using them already). You might also consider entering what you have produced into your favourite database modelling tool.
The method stages in more detail.
Preparation:
Collect whatever documentation you have for the system as a whole: Use Cases, Menu structures, anything! The important thing is not detail, but to get an overview of what the system is supposed to do.
“Brainstorm:”
Based on the material above, try to guess the tables/entities you will find in the database. Concentrate on the “Things” and “Transactions” categories described in my previous post.
Don’t spend ages doing this. Just long enough so you have an expectation of what you are looking for.
Remember that people may use different names for the same thing e.g. ORDER may be PURCHASE_ORDER, SALES_ORDER or SALE.
List the tables:
select name, object_id, type, type_desc, create_date, modify_date
from sys.tables
(try sys.Views as well)
Group the tables

Group the tables based on name: ORDER, ORDER_ITEM, SALES_ORDER, PURCHASE_ORDER and ORDER_ITEM would all go together.
Break the whole database into a number of “chunks”. Aim for each chunk to have say 10 members, but do what seems natural, rather than forcing a particular number. Expect to have a number of tables left over at the end. Put them in a “Miscellaneous” bucket.
Identify the candidate keys, and foreign keys from the indexes
select tab.name, idx.index_id, idx.name , idx.is_unique
from
sys.indexes as idx
join sys.tables as tab on tab.object_id = idx.object_id
where
tab.name like ‘%site%’;
select tab.name, col.column_id, col.name
from
sys.columns as col
Join sys.tables as tab on col.object_id = tab.object_id
where
tab.name like ‘%PhoneBook%’
order by 1, 2 ;
From attribute names and indexes, identify relationships

- Sometimes the index names are a give-way (FK_…)
- Sometimes you have to look for similar column names (ORDER_LINE.ORDER_ID à ORDER.ID)
- Multi-part indexes sometimes indicate hierarchies.
Push Out

Look for “Inter.group” Relationships